The UC Santa Cruz Genomics Institute is facilitating research into the novel coronavirus that has infected thousands of people since an outbreak began in Wuhan, China, last year. The Genomics Institute’s browser team has now posted the complete genome of the virus on the UCSC Genome Browser, an interactive web-based tool used by researchers all over the world to study genetic data.
“When we display coronavirus data in the UCSC Genome Browser, it lets researchers look at the virus’ structure and more importantly work with it so they can research how they want to attack it,” said UCSC Genome Browser Engineer Hiram Clawson.
The rapid spread of the 2019 novel coronavirus (2019-nCoV, also known as the Wuhan seafood market pneumonia virus) has prompted the Chinese government to quarantine more than 50 million people in the country’s dense industrial heartland. Samples of the virus have been processed in labs all over the world, and the raw information about its genetic code has been sent to the worldwide repository of genomic information at the National Institutes of Health’s National Center for Bioinformatics (NCBI) in Bethesda, Maryland.
“The NCBI is a worldwide repository established in the very early days of genomics,” said Clawson. “When people find novel viruses, they send them to the NCBI, and the NCBI assigns them a name and number so everyone can refer to an exact specimen. Once they’ve processed the genomic information, it’s made available to the world from the database.”
From there, the UC Santa Cruz Genome Browser processes the information into a visual display. The genome of the virus consists of 29,903 nucleotides—the bases that make up the DNA and RNA molecules that encode all life on earth.
“When we obtain this data from NCBI, it’s a single file with the letters in it from the DNA or RNA (A,C,G, and T),” Clawson said. “This one happens to be single-stranded RNA, a relatively simple structure.”
This information is processed and placed into a database, where the Genome Browser can access the material and display it in a web browser in a much more useful format.
“What makes the Genome Browser so valuable is that it is so visual,” Clawson said. “It makes it very clear where everything is, so when people make interesting measurements about the genome in the virus, they can see what they’re looking at,” Clawson said.
Researchers can zoom in and out of the genome. This allows them to see the sequence of bases at the most detailed level or zoom all the way out and see individual genes.
The browser also contains a CRISPR track, which allows researchers to see where they can splice genetic material and how they can cut it. With CRISPR technology, researchers can edit genetic material, a tremendously valuable tool for determining which genes do what.
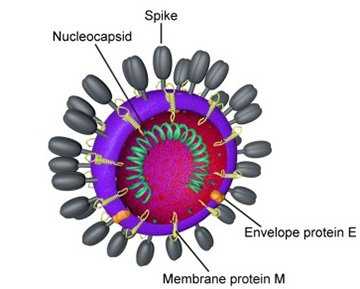
“In the case of this virus,” Clawson said, “there are approximately ten genes and the largest is its spike protein,” referring to the chemical spine which the virus uses to snag onto human cells and hijack their cellular machinery to reproduce itself. “So they might make a change to see if it makes the spike protein more or less virulent.”
The Browser also allows for annotation, so researchers all over the world can collaborate and share experimental information.
The UCSC Genome Browser is among the most important tools ever created by genomics researchers at UC Santa Cruz. By establishing a standard interface and protocols for examining genetic information, they’ve unlocked breakthroughs in bioinformatics and genetics laboratories all over the world.
For more information, visit the UCSC Genome Browser website at genome.ucsc.edu.


